L’intelligence artificielle n’est plus réservée aux géants de la technologie ou aux laboratoires de recherche. Que vous soyez entrepreneur cherchant à automatiser un processus métier ou développeur explorant de nouveaux horizons, concevoir une IA personnalisée est devenu un projet accessible. Passer de l’idée à un algorithme fonctionnel demande toutefois une méthodologie rigoureuse, loin des promesses simplistes d’outils miracles.
Définir l’objectif : le socle de votre projet
La question centrale est celle de l’utilité. Une intelligence artificielle est un outil conçu pour résoudre un problème spécifique : prédire des ventes, classer des images, automatiser un support client ou détecter des anomalies sur une ligne de production. Sans un objectif métier clair, vous risquez de construire un modèle performant sur le papier, mais inexploitable en conditions réelles.
Identifier le type de problème
La plupart des projets relèvent de l’apprentissage supervisé, divisé en deux familles : la classification et la régression. Si vous voulez que votre IA distingue des courriels légitimes des spams, vous utilisez la classification. Si vous cherchez à estimer le prix futur d’un actif immobilier, vous travaillez sur une régression. Identifier cette catégorie permet de restreindre le choix des algorithmes et de structurer la collecte de vos données.
Évaluer la faisabilité et le ROI
Créer une IA demande du temps et des ressources. Estimez si le gain de productivité justifie l’investissement. Une IA bien intégrée automatise souvent entre 70 % et 90 % des tâches répétitives d’un workflow. Si votre projet cible une tâche rare ou nécessitant une intuition humaine complexe, l’IA n’est peut-être pas la solution prioritaire. À l’inverse, pour des processus volumétriques et standardisés, le retour sur investissement est souvent visible dès la première année.
La donnée : le carburant de l’algorithme
La qualité de votre modèle dépend davantage de la pertinence de vos données que de la complexité de l’algorithme. Pour obtenir des résultats fiables, un seuil minimal de 10 000 points de données est souvent nécessaire, bien que ce chiffre varie selon la nature du projet.
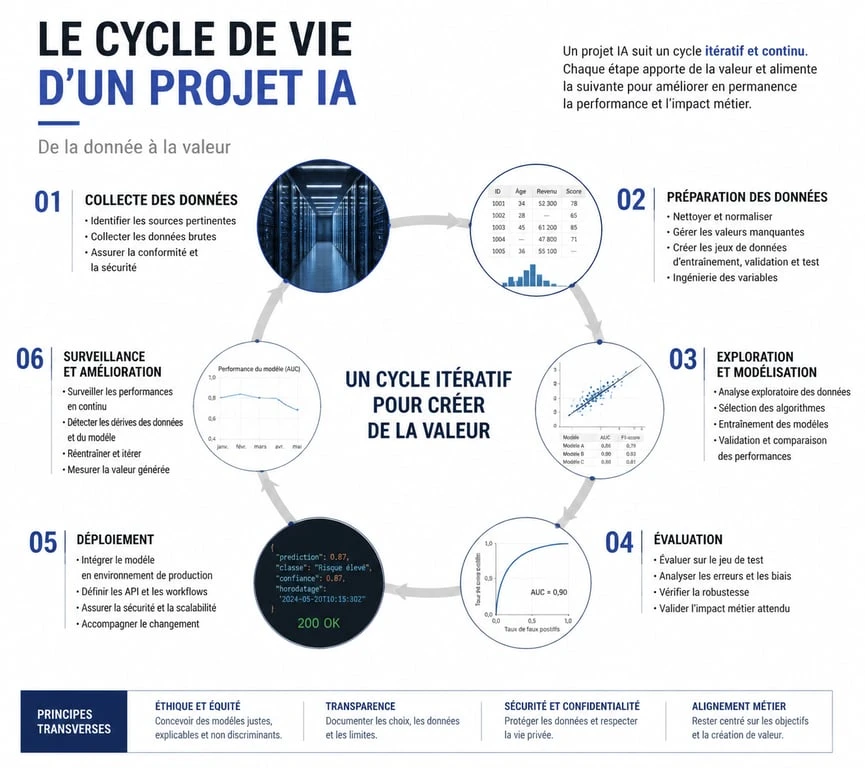
Collecte et préparation des datasets
La collecte consiste à rassembler des informations provenant de bases de données internes, d’API ou de fichiers structurés. Une fois réunies, ces données doivent être nettoyées : supprimez les doublons, traitez les valeurs manquantes et normalisez les formats. Si vos données sont hétérogènes, l’algorithme peinera à identifier les motifs récurrents nécessaires à son apprentissage.
La qualité de vos données agit comme une force d’attraction pour votre projet. Si elles sont biaisées ou insuffisantes, votre modèle déviera de sa trajectoire et produira des prédictions erronées. Un étiquetage précis et une représentativité réelle du terrain permettent à l’IA de rester alignée avec vos objectifs opérationnels, évitant ainsi des erreurs coûteuses.
L’importance de l’étiquetage
Dans l’apprentissage supervisé, vous devez fournir à l’IA la bonne réponse pour chaque exemple. C’est l’étape de l’étiquetage. Pour une IA de reconnaissance de défauts industriels, vous devez marquer manuellement des milliers d’images comme conformes ou défectueuses. Ce travail est le moteur de l’intelligence de votre système. Des outils de data labeling accélèrent le processus, mais une vérification humaine reste indispensable pour garantir la fiabilité.
Choisir la technologie : No-Code, API ou sur-mesure
Le choix de la pile technologique dépend de vos compétences, de votre budget et de la spécificité de votre besoin.
Les plateformes No-Code et Low-Code
Pour déployer une solution rapidement sans équipe de data scientists, le No-Code est une option efficace. Ces outils permettent de construire des modèles par glisser-déposer, réduisant les coûts de développement jusqu’à 70 %. Ils sont parfaits pour des cas d’usage standards comme la prédiction de désabonnement client ou l’analyse de sentiment. Ils offrent toutefois moins de flexibilité pour des besoins propriétaires complexes.
L’utilisation d’API et de modèles pré-entraînés
Des fournisseurs comme OpenAI, Google Cloud ou AWS proposent des modèles déjà entraînés sur des volumes de données massifs. Via des API, vous intégrez des capacités de compréhension du langage naturel ou de vision par ordinateur dans vos logiciels. C’est la solution la plus rapide pour ajouter une couche d’intelligence sans gérer l’infrastructure lourde d’entraînement.
Le développement personnalisé avec Python
Pour une maîtrise totale, Python reste la référence. Grâce à des frameworks comme TensorFlow, PyTorch ou Scikit-Learn, les développeurs conçoivent des architectures de réseaux de neurones sur-mesure. Cette approche est indispensable pour une innovation de rupture ou si vous manipulez des données sensibles nécessitant une conformité RGPD stricte sur vos propres serveurs.
| Approche | Avantages | Inconvénients | Public cible |
|---|---|---|---|
| No-Code | Rapidité, coût réduit | Flexibilité limitée | PME, Marketeurs |
| API / Pre-trained | Performances, scalabilité | Coûts récurrents | Développeurs Web |
| Custom (Python) | Contrôle total, IP | Expertise rare requise | Data Scientists |
Entraînement et évaluation : le cycle itératif
Une fois les données prêtes, l’algorithme digère les informations pour ajuster ses paramètres. Un modèle performant sur ses données d’entraînement ne garantit pas une réussite en production.
Éviter le sur-apprentissage
Le sur-apprentissage, ou overfitting, survient quand l’IA apprend par cœur vos données au lieu de comprendre les règles générales. Pour l’éviter, séparez votre dataset : 80 % pour l’entraînement et 20 % pour le test. Le jeu de test évalue l’IA sur des données inédites. Si les performances chutent sur ce second jeu, votre modèle est trop rigide et doit être simplifié.
Mesurer les performances réelles
La précision brute n’est pas toujours l’indicateur idéal. Dans la détection de maladies rares, une IA qui répondrait systématiquement négatif aurait une précision de 99 % tout en échouant sur les cas critiques. Utilisez des mesures comme le rappel ou le F1-score pour valider l’efficacité réelle de votre système par rapport aux enjeux de sécurité définis.
Déploiement et maintenance
La mise en production et la maintenance, souvent regroupées sous le terme MLOps, sont des étapes cruciales pour la pérennité de votre solution.
Intégration dans les workflows
Pour qu’une IA soit adoptée, elle doit s’intégrer naturellement dans les outils quotidiens. Que ce soit via une intégration CRM, une extension de navigateur ou une application mobile, l’interface doit permettre à l’utilisateur de comprendre la décision proposée. Cette explicabilité est le socle de la confiance des collaborateurs.
Le monitoring et la dérive du modèle
Le monde évolue, et vos données avec lui. Une IA entraînée sur des comportements d’achat pré-crise peut devenir obsolète en quelques mois. C’est la dérive, ou drift. Surveillez en continu les performances en production et prévoyez des cycles de ré-entraînement avec des données fraîches. Créer une intelligence artificielle est un processus continu d’amélioration et d’adaptation.
- Inbound Marketing : 5 étapes clés pour attirer et convertir vos prospects sans forcer - 15 juillet 2026
- Formation webmarketing : CPF, modules clés et débouchés à vérifier avant de choisir - 14 juillet 2026
- Dropshipping rentable ou budget perdu ? Niche, fournisseurs et premières ventes - 14 juillet 2026
Articles qui pourraient vous intéresser :
 Partage de fichiers en ligne : 4 leviers de sécurité pour neutraliser les risques de fuite
Partage de fichiers en ligne : 4 leviers de sécurité pour neutraliser les risques de fuite
 Blog technologie : 4 leviers pour filtrer l’innovation et maîtriser le bruit numérique
Blog technologie : 4 leviers pour filtrer l’innovation et maîtriser le bruit numérique
 Produit innovant : 4 critères de rupture et erreurs fatales lors du lancement
Produit innovant : 4 critères de rupture et erreurs fatales lors du lancement
 12 métiers en télétravail : les meilleures options pour gagner sa vie sans trajet
12 métiers en télétravail : les meilleures options pour gagner sa vie sans trajet